今天沒有引言,但是有梗圖

前天的文章介紹了基本的循環神經網路RNN,但RNN的致命缺點是容易導致梯度下降或是梯度爆炸。為了要解決這個問題,必須在以下兩點有所突破:
昨天的文章所介紹的長短期記憶神經網路模型選擇往第二點的方向突破,在神經網路節點中加入了輸入閥(input gate)、遺忘閥(forget gate)、以及輸出閥(output gate),這個做法可以有效地解決循環神經網路模型容易梯度下降或是梯度爆炸的缺點,但由於長短期記憶模型加入的參數過多,若透過大量的資料進行訓練,可能會導致模型運算量過大。那電腦科學家們為了降低運算成本以及減少佔用記憶體,同時又要維持相同的模型表現,於是就發明了GRU(Gate Recurrent Unit)。
GRU 也是循環神經網路 RNN 的另外一種變體,因此網路架構也跟 RNN 相差無幾,GRU 同樣有輸入層、隱藏層、以及輸出層,最大的差別只是在於其中的節點運算。
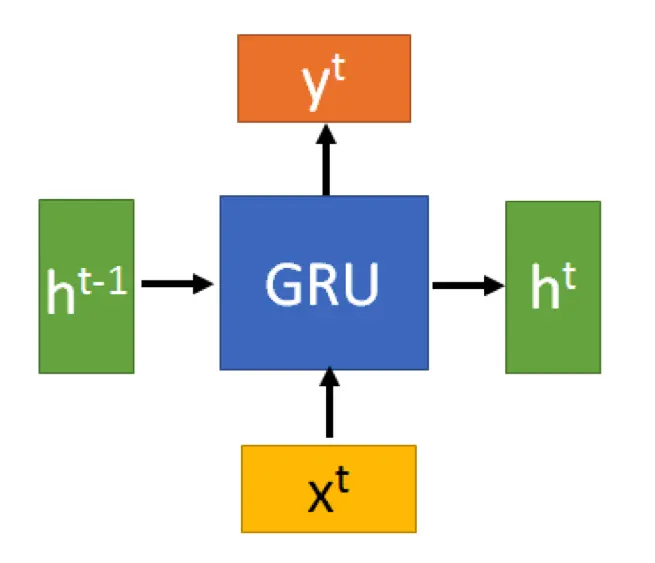
我們可以回想一下,在LSTM中,總共有三個門閥對資料進行「把關」,分別為輸入閥、遺忘閥,以及輸出閥;而在GRU中,同樣也有門閥,功能也是完全相同(皆為篩選記憶),只是三個變成了兩個,分別為重置閥(reset gate)以及更新閥,由於減少了門閥數量,因此運算量相對於LSTM來說,減輕了不少。
跟LSTM相同,我們先從GRU的兩個門閥開始,圖中的 是重置閥,
則為更新閥,兩者在各自的權重
乘上輸入
以及隱藏層
後,皆會經過激勵函數將數值變換成0-1之間的數字,篩選模型記憶的資訊,也就是說,這些數值代表節點對資訊的記憶程度。我們在這裡將
跟
計算出來之後,先放著備用。
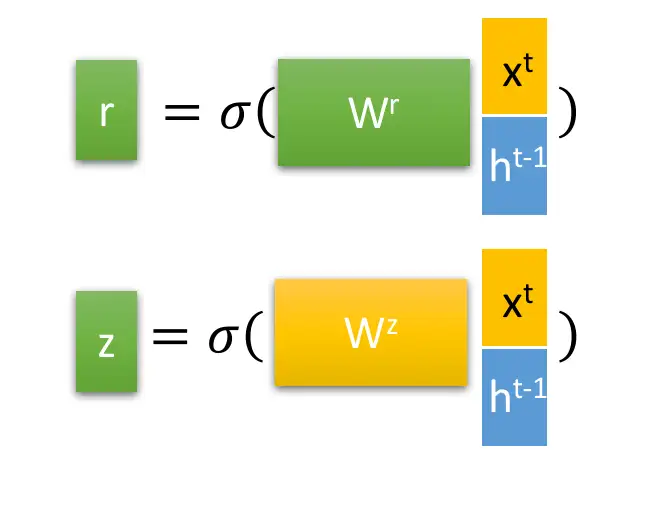
接下來讓我們進入節點的設計,前面有說到 GRU 從原本 LSTM 的三個門閥變成兩個門閥,所以以下會分成兩個階段來講解。
話不多說,先上圖!⊙ 代表矩陣相乘,⊕ 代表矩陣相加

請允許我把這部分用不到的路徑先遮蓋起來,這樣比較不容易迷路。
在這裡,我們會用到之前所計算的重置閥 (reset gate)。首先,當我們得到了重置閥r之後,要透過重置閥來「重置」上一個隱藏層傳來的資訊:

接著 與輸入
以及權重相乘後,再加入
的激勵函數,將資料壓到 [-1, 1] 之間,就會得到
。
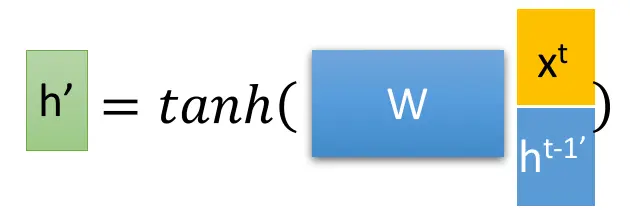

透過這個更新閥,就可以同時做到記憶以及遺忘的功能。在這裡,我們會用到之前所計算的更新閥 (update gate),在這裡的計算是:

其中更新閥的數值,因為sigmoid激勵函數的緣故,數值會介在[0, 1]之間,這代表GRU在這一層需要記憶的程度。越接近1代表記憶的資訊越多;越接近0代表遺忘的資訊越多。 不知你是否發現到,只要單單透過一個門閥,就可以同時控制遺忘以及選擇記憶,相對於LSTM要用多個門閥才能達到相同的效果,這就是為什麼GRU的計算成本可以低於LSTM的原因。



因為GRU用了比較少門閥的緣故,所以相對於長短期記憶LSTM來說,訓練的時間較短,佔用的記憶體也較少。只是模型表現上,兩者其實是差不多的。所以如果考量到訓練時間還有運算資源的限制的話,鐵定是毫不猶豫地選擇GRU的啦!

不過就像在Day 15: 圓圓圈圈圓圓~深度學習:循環神經網路 RNN中所說,這仍然無法解決模型無法理解下文與上文之間關係的問題。那人工智慧學家又是怎麼解決這個問題的呢?就讓我們等到明天介紹BiLSTM的文章再來聊吧!
若你有空,也歡迎來看看其他文章:
➡️ 【NLP】Day 16: 跟你我一樣選擇性記憶的神經網路?深度學習:長短期記憶 LSTM
➡️ 【NLP】Day 15: 圓圓圈圈圓圓~深度學習:循環神經網路 RNN
➡️ 【NLP】Day 14: 神經網路也會神機錯亂?不,只會精神錯亂...深度學習:前饋神經網路

